翻翻旧笔记整理一下线程相关知识
线程
定义
从操作系统的角度,可以认为线程是系统调度的最小单元,而进程是程序,一个进程可以包含多个线程,是任务的真正运作者,有自己的栈(Stack)、寄存器(Register)、本地存储(Thread local)等,会与进程内其他线程共享文件描述符、虚拟地址空间等。
多个线程共用进程的堆和方法区
生命周期
有新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)、死亡(Dead)五种状态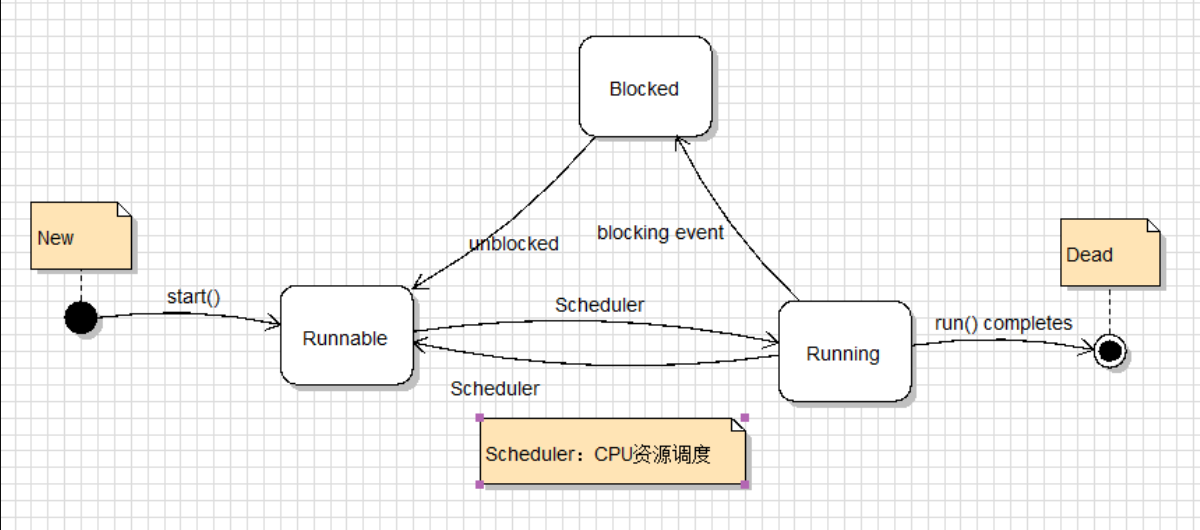
① 创建线程后,线程进入New状态,和普通对象一样,Java虚拟机会为其分配内存
② 调用start() 方法后,线程处于Runnable状态,可运行的,Java虚拟机会为其创建方法调用栈和程序计数器
③ 处于Runnable状态的线程获得CPU之后,开始执行方法体,处于Running运行状态
如果发生如下情况,线程会进入阻塞状态:
线程调用sleep方法主动放弃所占用的处理器资源。
线程调用了一个阻塞式IO方法,在该方法返回之前,该线程被阻塞。
线程试图获得一个同步监视器,但该同步监视器正被其他线程锁持有。关于同步监视器的知识将在后面有更深入的介绍。
线程在等待某个通知(notify)。
程序调用了线程的suspend方法将该线程挂起。不过这个方法容易导致死锁,所以程序应该尽量避免使用该方法。
当前线程被阻塞后,其他线程就可获得执行的机会,被阻塞线程会在合适的时候进入就绪状态,等待重新调度,解除阻塞的情况有:
调用sleep方法的线程经过了指定时间。
线程调用的阻塞式IO方法已经返回。
线程成功地获得了试图取得同步监视器。
线程正在等待某个通知时,其他线程发出了一个通知。
处于挂起状态的线程被调用了resume恢复方法。
④ 线程死亡 run()方法执行完成,线程正常结束,或抛出未捕获的Exception或Error
Java5之后,线程的状态在java.lang.Thread.State中的枚举中,我用的是8,看到有NEW、RUNNABLE、BLOCKED、WAITING、TIME_WAITING计时等待、TEAMINATED终止六种。
可以看到区分了等待状态,Waiting表示等待其他线程的操作,常用于生产者消费者模式,通常,消费者进入等待wait模式,等待生产者发出notify等操作告诉消费者可以继续工作。计时等待Time_Waiting与Waiting类似,但调用的时候存在超时条件。
守护线程
守护线程(Daemon Thread),Java中线程分两种守护线程和用户线程
有时候需要一个长期驻留的服务程序,但是不希望其影响应用,当Java虚拟机发现只有守护线程存在时,将结束进程。百度百科上的守护进程(or线程)有详细的定义,一般的网络服务都是以守护进程的方式运行
任何线程都可以设置为守护线程,可通过setDaemon()中的参数为true来设置:
1 | Thread daemonThread = new Thread(); |
垃圾回收线程是一个守护线程,如果只剩了守护线程,虚拟机会自动离开
基本用法
Java提供了三种创建线程的方法:
- 实现Runnable接口
- 继承Thread类本身
- 通过Callable和Future创建线程
其中最简单的方法就是继承Runnable,复写run()方法,
1 | class MyThread implements Runnable{ // 实现Runnable接口 |
你也可以在类中实例化一个线程对象,常用的构造方法带的参数:
1 | Thread(Runnable threadOb,String threadName); |
比如这样
1 | MyThread thread = new Mythread(); |
出现频率也很高的join()方法不得不说,他可以使得一个线程强行运行,期间其他线程无法运行。
休眠,sleep()方法必须要有InterruptedException异常处理,入参时间的单位为毫秒
yield()方法让线程放弃执行,将CPU的控制权让出
Runnable 和 Callable 有什么不同?
Runnable 和 Callable 都代表那些要在不同的线程中执行的任务。Runnable 从 JDK1.0 开始就有了,Callable 是在 JDK1.5 增加的。它们的主要区别是 Callable 的 call() 方法可以返回值和抛出异常,而 Runnable 的 run() 方法没有这些功能。Callable 可以返回装载有计算结果的 Future 对象。
但是,单独使用 Callable,无法在新线程中(new Thread(Runnable r))使用,Thread 类只支持 Runnable。不过 Callable 可以使用 ExecutorService 。
线程池
线程池种类
- newCachedThreadPool 创建一个可缓存的线程池,用来处理大量短时间任务的线程池;如果线程闲置的时间超过60秒,则被终止并移除缓存;长时间闲置时这种线程池不会消耗什么资源,在使用缓存型池时,先查看池中有没有以前创建的线程,如果有,就复用.如果没有,就新建新的线程加入池中
- newFixedThreadPool 创建一个定长线程池
- newScheduledThreadPool 创建一个定长线程池 定期和周期性的执行任务的线程池
- newSingleThreadExecutor 与newScheduledThreadPool的区别在于创建一个单线程化的线程池
- Java8之后加入了newWorkStealingPool(int parallelism) 线程池,其内部构建ForkJoinPool,利用Work-Stealing算法,并行的处理任务
ExecutorService
线程池管理者,ExecutorService接口继承了Executor接口.定义了一些生命周期的方法.我们能把Runnable,Callable提交到池中让其调度.
先说使用:
1 | // 比如创建一个定长线程池 |
看一下它的源码
1 | public interface ExecutorService extends Executor { |
但是!阿里巴巴开发规约中有一条说:
【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样
的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors 返回的线程池对象的弊端如下:
1)FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2)CachedThreadPool 和 ScheduledThreadPool:
允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
重点:推荐使用ThreadPoolExecutor
ThreadPoolExecutor
自定义线程池,参考https://www.jianshu.com/p/f030aa5d7a28下面讲解参数较全的一个构造方法
1 | public ThreadPoolExecutor(int corePoolSize, // 1 |
| 序号 | 名称 | 类型 | 含义 |
|---|---|---|---|
| 1 | corePoolSize | int | 核心线程池大小 |
| 2 | maximumPoolSize | int | 最大线程池大小 |
| 3 | keepAliveTime | long | 线程最大空闲时间 |
| 4 | unit | TimeUnit | 时间单位 |
| 5 | workQueue | BlockingQueue |
线程等待队列(阻塞队列) |
| 6 | threadFactory | ThreadFactory | 线程创建工厂 |
| 7 | handler | RejectedExecutionHandler | 拒绝策略 |
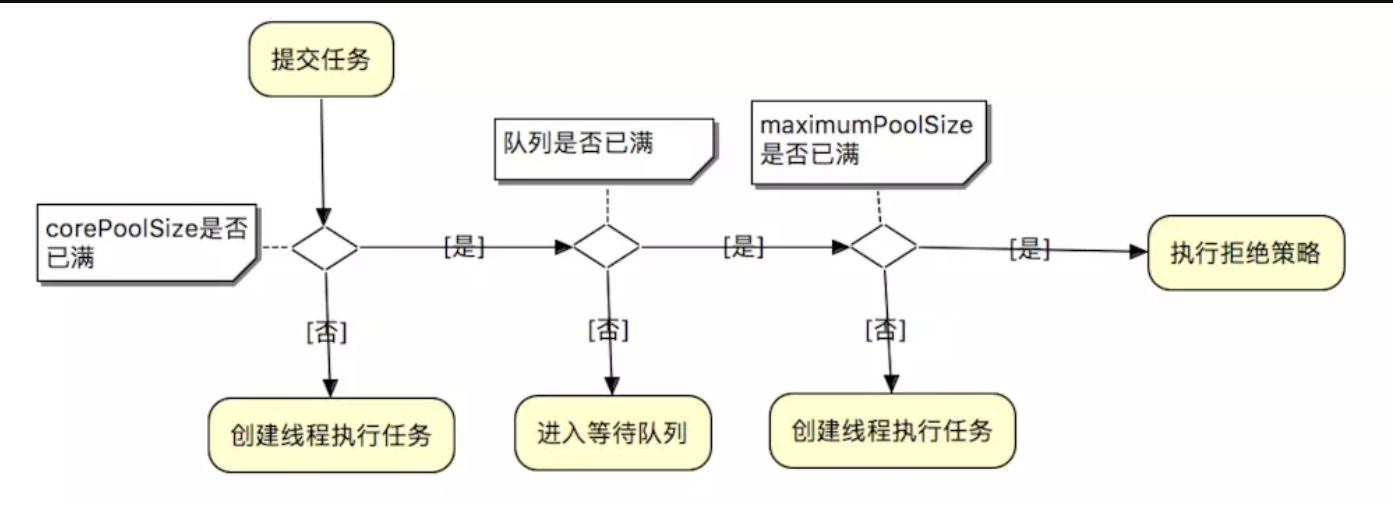
结合这张线程池处理流程图能更好的理解这些入参,keepAliveTime是超出核心线程池给予的时间,unit是keepAliveTime的单位,workQueue 阻塞队列,存放来不及处理的线程,有ArrayBlockingQueue,LinkedBlockingQueue,SynchronousQueue,PriorityBlockingQueue几种,handler,拒绝/饱和策略,有AborPolicy直接抛弃,CallerRunsPolicy用调用这线程执行,DiscardOldestPolicy抛弃队列中最久的任务,DiscardPolicy抛弃当前任务四种
ThreadLocal
通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。如果想实现每一个线程都有自己的专属本地变量该如何解决呢? JDK中提供的ThreadLocal类正是为了解决这样的问题。 ThreadLocal类主要解决的就是让每个线程绑定自己的值,可以将ThreadLocal类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。
如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是ThreadLocal变量名的由来。他们可以使用 get() 和 set() 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。
比如
但是,又要说但是了,看到阿里规约中
【参考】ThreadLocal 无法解决共享对象的更新问题,ThreadLocal 对象建议使用 static
修饰。这个变量是针对一个线程内所有操作共享的,所以设置为静态变量,所有此类实例共享
此静态变量 ,也就是说在类第一次被使用时装载,只分配一块存储空间,所有此类的对象(只
要是这个线程内定义的)都可以操控这个变量。
小结
有效利用多线程的关键是理解程序是并发执行而不是串行执行的。例如:程序中有两个子系统需要并发执行,这时候就需要利用多线程编程。
通过对多线程的使用,可以编写出非常高效的程序。不过请注意,如果你创建太多的线程,程序执行的效率实际上是降低了,而不是提升了。
请记住,上下文的切换开销也很重要,如果你创建了太多的线程,CPU 花费在上下文的切换的时间将多于执行程序的时间!
其他
什么是上下文切换
多线程会共同使用一组计算机上的 CPU ,而线程数大于给程序分配的 CPU 数量时,为了让各个线程都有执行的机会,就需要轮转使用 CPU 。
不同的线程切换使用 CPU 发生的切换数据等,就是上下文切换。
在上下文切换过程中,CPU 会停止处理当前运行的程序,并保存当前程序运行的具体位置以便之后继续运行。从这个角度来看,上下文切换有点像我们同时阅读几本书,在来回切换书本的同时我们需要记住每本书当前读到的页码。
如何结束线程
可以使用interrupt()来中断一个正在执行的线程,它可以使一个被阻塞的线程抛出一个中断异常,从而使线程提前结束阻塞状态,退出堵塞代码。
如何使用 wait + notify 实现通知机制?
我们知道,java的wait/notify的通知机制可以用来实现线程间通信。wait表示线程的等待,调用该方法会导致线程阻塞,直至另一线程调用notify或notifyAll方法才可另其继续执行。经典的生产者、消费者模式即是使用wait/notify机制得以完成。
1 | public class ThreadTest { |
两个注意点:
1)wait、notify 方法是针对对象的
2)wait、notify 方法必须在 synchronized 块或方法中被调用
SpringBoot中的自定义线程池
ThreadPoolTaskExecutor是spring core包中的,而ThreadPoolExecutor是JDK中的JUC。ThreadPoolTaskExecutor是对ThreadPoolExecutor进行了封装处理。
ThreadPoolTaskExecutor,创建线程池:
1 |
|
在需要的地方用@Async注解使用即可
- 无返回值的任务使用execute(Runnable)
- 有返回值的任务使用submit(Runnable)