开这篇的起因是因为工作中真的遇到了很多大大小小的问题,平时有空我都会记录下来,但由于又不是很重要或者很难的东西,(一切都源于我菜才会有这些问题),不想为这些分别立一篇,但还是有记录的价值的!(记录了自己成长哈哈哈)
我会按照内容来做标题,也会按照时间倒序,这篇的开始为19/2/13,所以一些小问题以后就不会立一篇博客了,只有当我觉得很重要的东西才会不放在这里面。
当然,每一个bug解决不可能完全不依赖谷歌百度,我会记录原文地址。
部署jar包
nohup java -jar XXX.jar
启动疯狂报Error creating bean
前一段时间拿到前人的代码之后,有个特别坑的地方就是在服务器上跑起来的时候出现疯狂报错,排查了很久最后还是其他大佬帮忙照出了问题,先放个当时的报错:
循环报许多类的error creating bean ,而真正的问题出在java.util.ConcurrentModificationException
1 | 2019-07-01 11:19:27,870 [nioEventLoopGroup-5-1] WARN [io.netty.channel.AbstractChannelHandlerContext] - An exception 'java.util.ConcurrentModificationException' [enable DEBUG level for full stacktrace] was thrown by a user handler's exceptionCaught() method while handling the following exception: |
问题出在多线程中对同一个list用了迭代器并进行了修改长度的操作,要合理使用线程池以及对集合的使用
Mybatis如何设置联合主键(多主键)
由于Mybatis查询会根据结果集中的id进行unique过滤,而id又只能设置一个,会导致多主键情况下sql结果与真实的Mybatis结果不符,在Mybatis中多主键就把它当作没主键就行
Mysql error code 1366
1 | ### Error updating database. Cause: java.sql.SQLException: Incorrect string value: '\xE6\x9D\xA5\xE8\x87\xAA...' for column 'content' at row 1 |
这里content设为text格式,字符编码应为utf-8,默认是latin不支持中文,会报1366错
Mybatis OrderBy问题
多条件排序
example.setOrderByClauser(“timestamp DESC, name ASC”);
如何将一个bean的属性赋给另一个bean
两个类的属性不一定全部相同,但希望相同的属性中能映射过去。
Spring的BeanUtils.copyProperties()方法
如何判断一个元素在数组中
indexOf()若大于零则存在
IDEA中WebApplication:Exploded与Archive区别
原文:https://blog.csdn.net/ydk888888/article/details/77247725
对这个问题的疑惑是当时有个同事交接给我项目时,用IDEA跑普通maven项目起不来,于是以为是artifacts配置的问题,设置的地方在IDEA右上角有个蓝色俄罗斯方块的文件夹-Project Settings-Artifacts,就产生了疑惑,WebApplication:Exploded和WebApplication:Archive有啥区别?
/111.png)
直接引用原博客的话:
选项中有web application exploded,这个是以文件夹形式(War Exploded)发布项目,选择这个,发布项目时就会自动生成文件夹在指定的output directory,
如果选web application archive,就是war包形式,每次都会重新打包全部的,将项目打成一个war包在指定位置;
git Warning detached HEAD
原文:https://www.jianshu.com/p/ae4857d2f868
提交代码的时候遇到了Warning,没有贴原句,就拿这个原文中的复制过来,是这样的:
1 | Warning: you are leaving 1 commit behind, not connected to |
原本应该上传到master分支,但commit时出现了这个Warning导致没有成功,当时也没来得及看这段话,只看到git提交记录中自己的那个分支上右侧tag显示了一个黄色的感叹号,且无法push,当时急忙着checkout了版本库里的master分支看发现果然没有自己commit的那条,返回本地分支回去发现自己辛辛苦苦写了两天的代码就没了,突然愣住,找了其他大佬说应该是找不回来了,于是回去翻看到这个warning,找到这篇简书。
按照步骤第一步输入,xxxx就是这个Warning里的版本号
1 | $git branch temp xxxx |
第二步切换工作分支并合并代码
1 | git checkout master |
最后删除temp分支
但是!我发现自己创的temp分支根本和这篇里的不一样,我只是创了一个temp 但并没有我原来的那个代码,以为这个方法也凉凉,但还是坚信代码能找回来!毕竟commit过,怎么会丢呢?
首先我们分析一下这个Warning,git把我们新的提交已经创好了一个版本号,但是实际上这个版本没有完全成功因为他说没有提交到任一分支,(奇怪我坚信自己肯定是选了,和平时操作一样),但这个编号为xxxx的commit实际上是肯定存在某个地方的,git也建议我们使用temp分支来解决这个问题,所以解决思路应该没问题
最后意识到自己在遇到这个Warning后又自己checkout了master分支又切回来多次,所以当下的git状态可能没有之前我commit的这条xxxx,所以创建temp分支会有语法错误,于是git log找到当时我提交的那个head 版本号,再reset回去,保险起见我在IDEA里右击-git-reset里退回(防止我自己敲错)然后再按照上面的步骤重新合并,成功!
花了差不多半个小时挽回了自己两天的代码…
sublist()
List中有个sublist方法的小标为左闭右开
git 无法重输密码的问题
公司内网gitlab代码down不下来,因为一段时间没用gitlab,可能第一次输密码的时候错了,导致怎么都拉不下来代码,想重新输入又没有跳出来弹框,在外面用命令直接输出现Authentication failed。于是按照https://blog.csdn.net/qq_40028324/article/details/80883010将密码清空之后再输一次就成功了。
log占位符
研究大佬们代码发现他们log放参数的方法没有见过,是这个样子:
1 | logger.info("xxxxxx:{}",obj.getXXX()); |
这种大括号的占位符方式是log特有的,非常方便,多参数还可以加上序号区分
1 | LOGGER.log(Level.INFO,"{0}{1}{2}",new Object[]{"刘利新",System.getProperty("line.separator"),"西安"}); |
来自https://blog.csdn.net/weiyanghuadi/article/details/9271447
IDEA常用快捷键
Ctrl+Shift+Backspace,跳转到上次编辑的地方
F2 或 Shift+F2,高亮错误或警告快速定位
Alt+Shift+Up/Down,上/下移一行
String Date和Timestamp转化
因为原文真的太详细了,实在不忍心复制黏贴下来,请查阅原文:https://www.cnblogs.com/qima/p/3652566.html
另外timestamp的单位为秒或毫秒
数据库datetime类型的set方法
datetime类型在java中导入用setTimestamp()方法
util.Date与sql.Date转化
数据库中拿到的Date是sql包的,赋给util.Date时会报错,转换方法:
1 | sqlDate = new Timestamp(utilDate.getTime()); |
同时,两者均可被SimpleDateFormat格式化
设置Date时间
这边是设置Date时分秒为0的方法:
1 | Date tradeDay = candleStick.getTradeDay(); |
List与ArrayList的区别
https://www.cnblogs.com/zcscnn/p/7743507.html
这些基础知识有些忘了,今天看代码时突然不明白为什么通常使用
1 | List list = new ArrayList() |
找到这篇博客复习了集合,ArrayList是List的实现类,而作为接口List的扩展性是很好的
java8中stream,filter遍历代替for
今天看代码又发现一处没见过的写法:
1 | List<QuotesConfigTimeSubsection> subsectionList = tradeTime.stream() |
了解了这种新特性的写法,看上去的确比for来的清爽的多
stream().filter可过滤一个满足某条件的集合并赋值,
stream().map可直接遍历一整个集合并赋值
另外还有filtermap还没用过
#######################分割线########################
今天来操练一下流式写法👨💻
lambda
语法
1 | () -> expression; |
左侧为参数,如果不需要参数也可以为空,右侧是lambda代码块;如果只有一个返回时不需要特别声明,但若有条件分支的情况下需要视情况return;后面是表达式,或者一个代码块
1 | (params) -> expression |
如果对参数不需要进行修改的话就是简单的匿名内部类,比如监听事件:
1 | // Java 8之前: |
迭代
1 | .forEach() |
例:
1 | for(ChannelStudentInfo info : infos) { |
::
对象::实例方法
类::静态方法
类::实例方法
将方法名和对象分割开来
System.out::println
流式
前面大致了解了一点基本的lambda表达式的语法,主要还是来掌握java8的流式处理:
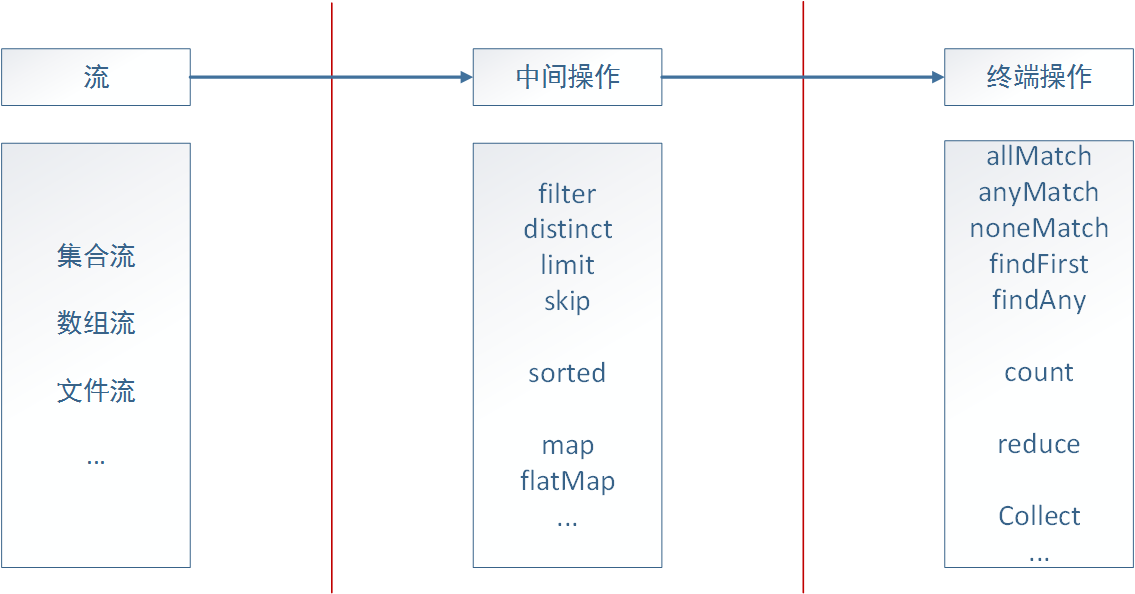
stream()
一个流式处理的操作首先是要调用stream()函数将集合(或数组,文件等)转化为流
然后再调用相应的中间操作达到我们需要对集合进行的操作
中间操作
也就是条件筛选,java8提供的筛选操作包括:filter、distinct、limit、skip,筛选的条件都用lamda表达式写
- filter()
相当于if()
- disctinct()
相当于sql的distinct,去重
- limit()
limit(n):返回包含前n个元素的流
- skip()
与limit相反,跳过前n个元素
- sorted()
排序,例如想对流内数据进行年龄从小到大操作:.sorted((s1, s2) -> s1.getAge() - s2.getAge())
终端操作
用到频率最高的是collect(),可以这样使用:collect(Collectors.toList())or collect(Collectors.toSet())orcollect(Collectors.toMap())
通俗易懂,就不解释了
流式处理的好处
(1)代码的可读性变高了,虽然也看到不少对于纯流式写法的吐槽,对于刚接触的人比如现在的我而言,把三四行并一行可读性的确提升了,但把十多行并一块就让人觉得有些吃力,debug的时候也会麻烦一些。
(2)流式处理的意义绝不可能是单单为了好看这么简单,其真正的特点是一个环节处理完的内容可以立马交给下一个环节处理,而不用等所有数据都处理完再进入下一个流程,应该是加快了运行速度
传统的for循环遍历,不仅需要等全部for循环完成后才能处理下一步,而且在for循环遍历时,只能使用一个核,通过将集合转化成流(通过实际观察,集合转成流本质上是new一个新对象的所需的时间耗时极少),转成流后,就可以充分利用流式处理的特点,显著的提高程序的响应速度,特别对于大数据业务耗时久的集合操作可以提高十倍甚至百倍的响应速度。
————————————————
版权声明:本文为CSDN博主「timchen525」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/timchen525/article/details/75041328
#######################分割线########################
sql中 Limit1的作用
在某些情况下,如果明知道查询结果只有一个,SQL语句中使用LIMIT 1会提高查询效率。 只要找到了对应的一条记录,就不会继续向下扫描了,效率会大大提高。
如果email是索引的话,就不需要加上LIMIT 1,如果是根据主键查询一条记录也不需要LIMIT 1,主键也是索引
当然,还有最简单的应用是只找出一个
SpringBoot接收Date型入参和出参
可以在JavaBean中对Date型数据加注解达到控制入参出参格式的作用:
1 | @DateTimeFormat(pattern="yyyy-MM-dd HH:mm:ss") |