转眼三月了 又到了樱花飘落的季节?昨天高中舍友翻出了当年小纸条拍给我看 没想到我还有那样疯狂杀马特的年纪啊
很多东西都变了 不变的是我的文笔和字还是这么烂 很多事都是第一次接触 给人一种很不真实的感觉 不再有人告诉你该怎么做 该好好学数学 学英语 做题 锻炼 吃有营养的食物… 连现在坐在这做对着电脑码bug 都给人一种很不可思议的感觉
这些都是一些废话 随口一说 今天有时间划水 想把上个礼拜看到的一个东东摸清楚——ConcurrentHashMap 说来惭愧 我之前似乎从来没见过这个类 第一眼看到百度了一下有了个大概的概念是用于并发的HashMap 天呐并发这块我真的是一点都不懂 持续利用搜索引擎打开新篇章(σ゚∀゚)σ…不 这回get了一个新技能 Ctrl Shift Alt + U 查看包 这图画的也太清晰了 可以说是相当方便了
Java提供了并发包java.util.concurrent 在用ConcurrentHashMap时可以看到引入的时候是1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
<img src="深入了解ConcurrentHashMap/1.png">
util.Collection的三个直系子接口:Set,List,Queue
Set为数字意义上的集合 没有重复项 List则为允许重复项的有序集合 Queue 接触的不多 队列 先进先出 主要是它的一个数据结构 这些直系子接口下能与支持并发挂上钩的 只有Vector(Vetor是个同步容器类)
> 题外话:为什么Vector我们总是不用呢?明明他是安全的 而且读取得也很快
> 是的 他安全,所以效率低 类似于StringBuffer 她和ArrayList是亲姐妹 但修改操作的效率却远低于ArrayList
> 另外分配内存时需要连续的存储空间
> ArrayList的增长量默认0.5倍 而Vector是一倍
> 总得来说是个比较死板的List 也难怪大家都不爱用她了
在这之前的推荐的线程安全的实现方式有Collections.synchronizedMap 和HashTable (但HashTable效率也比较低)今天的主角所在的concurrent包说来应该是个混血 虽然祖辈和集合有点联系 但它的结构来自于HashMap 父亲ConcurrentMap是从JDK5开始增加的线程安全的Map接口
**1.8之前**
## 结构
一个ConcurrentHashMap由一个个Segment组成 可以理解为一个Segment数组 Segment通过继承ReentrantLock 来实现加锁 每次锁住的是一个segment
```java
static class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
final float loadFactor;
Segment(float lf) { this.loadFactor = lf; }
}
concurrencyLevel 并发数目 即Segment个数 默认为16个 一旦初始化不能扩容 在一个三入参的构造方法里可以初始化这个值 注意,Java 需要它是 2 的幂次方,如果输入是类似 15则会自动调整到临近的2的幂次方
1 | public ConcurrentHashMap(int initialCapacity, |
initialCapacity 初始容量 会平均分给每个Segment
loadFactor 负载系数 这个我们稍后详细看看是什么来的
从他的结构就可以看出与HashTable相比 做并发操作时有了更多选择 因为HashTable只是竞争同一把锁 而ConcurrentHashMap默认会有十六个选择 这就是分离锁的作用 当一个线程访问其中一段数据的时候 其他段的数据也能被其他线程访问
扩容
这要首先讲讲HashMap的机制
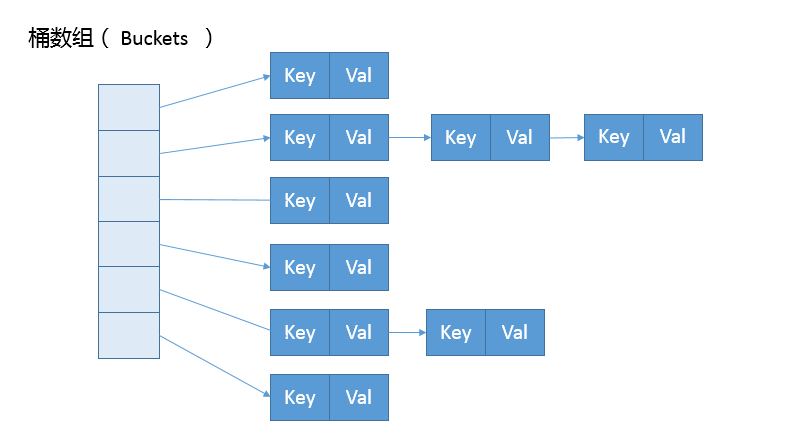
一个HashMap可以看做是key-value数组 但数组内部的形式上是链表组合的结构 通过计算哈希值决定了寻址 当得到一个地址并进入插入时 若发现这块存储地址已经被其他元素占用 就会找一块未被占用的存储地址 用链表的方式跟在后面
在这解释为什么刚才说ConcurrentHashMap的concurrencyLevel会是2的幂次方 这和HashMap的数组初始化长度如出一辙 因为这样可以更好地减少key之间的碰撞 key经过计算之后获取的哈希值在寻址之前要与数组长度2^n-1做与运算(比如16长度则与1110做与运算) 若不满2^n位则有较大几率产生相同结果 比如哈希值为8(1000)和9(1001)与1110与运算结果相同 这就产生了碰撞 这会导致哈希值为9的这块地址无法存放元素 产生了浪费 也减慢了查询的效率
初始的数组(也叫作桶bucket)+ 链表 组成了HashMap
当一个HashMap中元素越来越多,碰撞的几率也越来越高,就要对初始数组进行扩容 也就是resize操作 初始容量initialCapacity与负载因子loadFactor决定了它何时扩容
初始时 initialCapacity = 0 当要塞元素时 执行resize 初始容量设置为 threshold 16
继续塞 当元素数量超过 initialCapacity loadFactory = 16 0.75 = 12 时 执行resize 容量 -> threshold = 2*16 = 32
当容量算出来之后会初始化一个新的长度的桶数组 将键值对重新映射到新的桶数组中
以上就是作为一个普通的HashMap所遇到的扩容问题 那么ConcurrentHashMap是如何操作扩容的呢? 不是整体扩容 而是对每个segment扩容 为了支持多线程 ConcurrentHashMap有个 sizeCtl 字段会在未初始化、初始化中和扩容中用不同的数字表示状态
1.8之后
JDK8后的ConcurrentHashMap可以说是脱胎换骨 但在了解变化之前要先来看看HashMap在1.8之后做了什么
HashMap 从原先的 数组 + 链表 变为 数组 + 链表 + 红黑树 当链表根的长度超过8时会转化为树 (๑Ő௰Ő๑)真是做梦都没想到我还能看到红黑树这么深奥的东东了?
1 | /** |
真是庆幸自己能看到这篇文章 大神讲解的十分详细 连图都是这么优美 相比我自己写的实在是太垃圾了 (((;꒪ꈊ꒪;)))另外关于红黑树大神也有一篇博客 真的强推! 今天把这个放一下等周末有大把时间再来琢磨
回到主题ConcurrentHashMap在JDK1.8之后也沿袭了HashMap的结构 抛弃了Segment(但如今还是能在源码中看到Segment是为了保证序列化时的兼容 实际上已没有用处)初始化简化为懒加载 使用CAS
说到懒加载 上一篇博客讲的单例就是非懒加载
懒加载:对象使用的时候才去创建。节省资源,但是不利于提前发现错误
非懒加载:容器启动时立马创建。消耗资源,有利于提前发现错误错误非常关键,所以一般来说都用非懒加载的方式
CAS
参考原文:https://blog.csdn.net/weixin_42636552/article/details/82383272
CAS:Compare and Swap 意为比价交换 java.util.concurrent包中接住CAS实现了区别于synchronouse的一种乐观锁
无锁的概念
在谈论无锁概念时,总会关联起乐观派与悲观派,对于乐观派而言,他们认为事情总会往好的方向发展,总是认为坏的情况发生的概率特别小,可以无所顾忌地做事,但对于悲观派而已,他们总会认为发展事态如果不及时控制,以后就无法挽回了,即使无法挽回的局面几乎不可能发生。
这两种派系映射到并发编程中就如同加锁与无锁的策略,即加锁是一种悲观策略,无锁是一种乐观策略,因为对于加锁的并发程序来说,它们总是认为每次访问共享资源时总会发生冲突,因此必须对每一次数据操作实施加锁策略。
而无锁则总是假设对共享资源的访问没有冲突,线程可以不停执行,无需加锁,无需等待,一旦发现冲突,无锁策略则采用一种称为CAS的技术来保证线程执行的安全性,这项CAS技术就是无锁策略实现的关键,下面我们进一步了解CAS技术的奇妙之处。
CAS有三个参数:
1 | /** |
如果V == E,则将V设置为N。若V != E 这说明已经有其他线程做了更新,则当前线程什么都不做
由于CAS操作属于乐观派,它总认为自己可以成功完成操作,当多个线程同时使用CAS操作一个变量时,只有一个会胜出,并成功更新,其余均会失败,但失败的线程并不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作,这点从图中也可以看出来。基于这样的原理,CAS操作即使没有锁,同样知道其他线程对共享资源操作影响,并执行相应的处理措施。同时从这点也可以看出,由于无锁操作中没有锁的存在,因此不可能出现死锁的情况,也就是说无锁操作天生免疫死锁。
另外会不会发生这边写着V那边读的情况呢?是有可能的 但因为CAS是原语 (这一点将Compare and Swap放到有道词典里一搜就能知道)故不会产生不一致的问题
在没有锁的机制下,需要借助volatile原语来保证线程间的数据是可见 共享的
1 | static class Node<K,V> implements Map.Entry<K,V> { |
应用
1 | final V putVal(K key, V value, boolean onlyIfAbsent) { |
1 | private final Node<K,V>[] initTable() { |
用了前后三天时间写了这个博客 感觉越深入越感觉自己不会的有很多 在这之前我可能连HashMap的结构都不清楚 现在还遗留了很多未打开的话题 比如volatile 自旋锁与偏向锁 红黑树等等 开这篇博客的原因是从公司大哥代码里看到的 是从zookeeper中拿的数据放在了ConcurrentHashMap中 一边这边刷新数据赋值的同时当前系统可能有并发的读取 所以用了高效的ConcurrentHashMap
但要真的理解和掌握肯定不是这么粗粗地看一眼就学会的 手边有Java并发编程和Java36讲 在36讲刚出来的时候订阅却看不懂什么 现在居然也可以跟着慢慢磨懂了 还是挺开心的 另外我的写作水平有待加强 废话有点多 不够清晰 不加标点符号成了习惯看上去也有点费劲 我会慢慢改正的!有什么意见和建议欢迎留言呀!